最近在是有xgboost训练数据。在特征预处理阶段使用了OneHotEncoder来处理nominal类型的分类特征,模型训练好以后需要反过来分析特征,那么需要将原始数据中的特征与编码数据的特征对应起来。那么OneHotEncoder是怎么对应起来的呢?
通过其官方的例子分析了一下,下面记录如下。
original data:原始数据。
encode data:经过one hot编码以后的数据。
本文要分析的就是OneHotEncoder怎么将数据从original data变成encode data的。其规则如下:
- 编码后的特征prepend在新数据上,并删除原始特征。非分类特征直接保留
original data中每个分类特征可以编码成新特征的个数依次记录在n_values_属性中original data中每个分类特征在encode data中对应的新的特征维度选取方式记录在feature_indices_中
1 | from sklearn.preprocessing import OneHotEncoder |
方法如下图所示
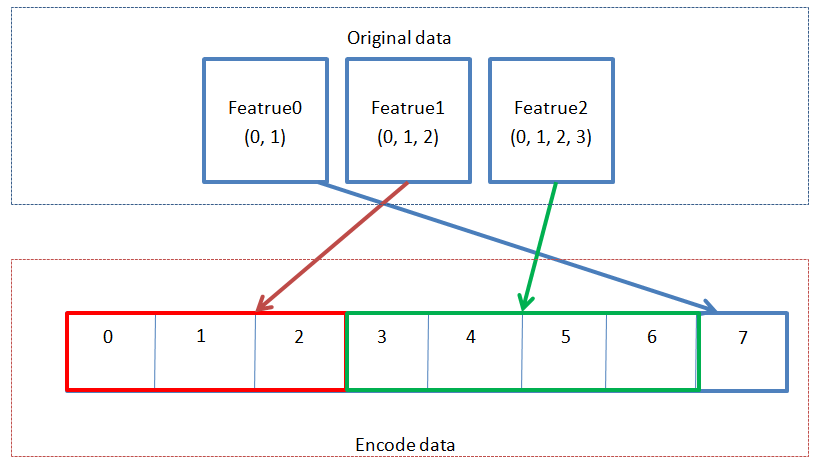
如上例子:
original data中第1、2两个维度为分类特征categorical_features=[1, 2]。- 这两个特征每个特征包含的可能的值的数量分别为3和4。
n_values: [3 4] - 产生的新的特征被prepend在
encode data中靠前的若干列中。feature_indices: [0 3 7]:- 原始特征的 首个分类特征 Feature1 => EncodeData[:, 0: 3]
- 原始特征的 第二个分类特征 Feature2 => EncodeData[:, 3: 7]
参考资料