ndarray 数组是我们用python进行科学计算时常用的数据类型,对它的深入了解是非常必要的。本文回顾之前学习的有关adarray的知识。
内存结构
ndarray 的内存结构如下图所示:
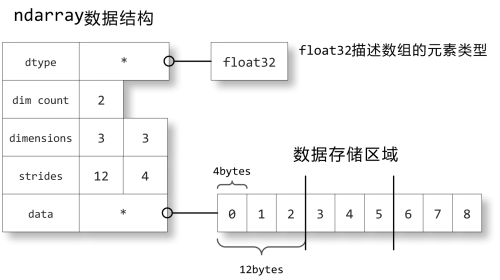
- data:指向数组中元素的二进制数据块。
- dtype:定义了数组中存放的对象的数据类型,通过它可以知道如何将元素的二进制数据转换为可用的值。如上图每32位表示一个有用数据
- dim count: 表示数组维数,上图为2维数组 (对应ndarray的属性
ndim) - dimmension: 数组的形状,3×3给出数组的(对应ndarray的属性
shape) - strides: 保存的是当每个轴的下标增加1时,数据存储区中的指针所增加的字节数。例如图中的strides为12,4,即第0轴的下标增加1时,数据的地址增加12个字节:即a[1,0]的地址比a[0,0]的地址要高12个字节,正好是3个单精度浮点数的总字节数;第1轴下标增加1时,数据的地址增加4个字节,正好是单精度浮点数的字节数。
dtype
dtype(数据类型)是一个特殊的对象,它含有ndarray将一块内存解释为特定数据类型所需的信息。
可以通过ndarray的astype方法显式地转换其dtype。
1 | import numpy as np |
numpy 有多种预定义的dtype(用的比较多的还是np.float64),需要的时候可以自行查找
还可以自定义数组的dtype。
strides再说明
有时ndarray中的数据并不一定都是连续储存的,通过下标范围得到新的数组是原始数组的视图(类似于引用),即它和原始视图共享数据存储区域, 对于新数组来说,其中的数据不一定是连续存储的。如下所示:
1 | import numpy as np |
由于数组b和数组a共享数据存储区,而b中的第0轴和第1轴都是数组a中隔一个元素取一个,因此数组b的strides变成了24,8,正好都是数组a的两倍。
元素在数据存储区中的排列格式有两种:C语言格式和Fortan语言格式。在C语言中,多维数组的第0轴是最上位的,即第0轴的下标增加1时,元素的地址增加的字节数最多;而Fortan语言的多维数组的第0轴是最下位的,即第0轴的下标增加1时,地址只增加一个元素的字节数。在NumPy中,元素在内存中的排列缺省是以C语言格式存储的,如果你希望改为Fortan格式的话,只需要给数组传递order=”F”参数:
1 | c = np.array([[0,1,2],[3,4,5],[6,7,8]], dtype=np.float32, order="C") |
ndarray的创建
创建ndarray对象的常用函数如下所示:
1 | np.array |
示例代码如下:
1 | np.arange(0,1,0.1) |
ndarray元素的索引
ndarray提供了三种索引方法。
切片索引
通过下标范围获取的新的数组是原始数组的一个视图。它与原始数组共享同一块数据空间,所以对 索引数组的修改 就是对原始数组的修改。
如果你想要得到的是ndarray切片的一份副本而非视图,就需要显式地进行复制操作,例如arr[5:8].copy()。
1 | a = np.arange(10) |
花式索引(整数序列)
当使用整数序列对数组元素进行存取时,将使用整数序列中的每个元素作为下标,整数序列可以是列表或者数组。
使用整数序列作为下标获得的数组不和原始数组共享数据空间。
1 | x = np.arange(10,1,-1) |
布尔索引(布尔数组 & 布尔列表)
当使用布尔数组b作为下标存取数组x中的元素时,将收集数组x中所有在数组b中对应下标为True的元素。
使用布尔数组作为下标获得的数组和原始数组共享数据空间,注意这种方式只对应于布尔数组
不能使用布尔列表, 否则会把True当作1, False当作0,按照整数序列方式获取原始中的元素,不共享内存
1 | x = np.arange(5,0,-1) |
布尔数组 索引可以使用逻辑运算, 分别为 |, &, ~ (或 与 非)。不能使用 and or not
1 | names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe']) # 七个人 ,有重复 |
参考资料
利用python进行数据分析